Розгортання Ollama та Open WebUI на VPS: покрокова інструкція зі створення приватного AI-чату
TL;DR
У цій інструкції описано процес розгортання повністю автономної та приватної екосистеми штучного інтелекту на базі Ollama (бекенд для запуску LLM) та Open WebUI (сучасний інтерфейс у стилі ChatGPT) на віртуальному сервері (VPS). Це рішення дозволяє виключити передачу даних стороннім компаніям, обійти цензурні обмеження хмарних моделей та отримати повний контроль над своїми даними та обчислювальними ресурсами.
- Повна приватність: Ваші запити та документи для RAG не покидають межі вашого сервера.
- Економія: Відсутність щомісячних підписок (ChatGPT Plus, Claude Pro) при використанні власних потужностей.
- Гнучкість: Можливість запускати будь-які відкриті моделі: Llama 3.x, Mistral, DeepSeek, Gemma та спеціалізовані кодинг-асистенти.
- Інтеграція: Готова API-сумісність з OpenAI API для підключення сторонніх програм до вашого сервера.
- Масштабованість: Легкий перехід від CPU-інференсу до повноцінного використання GPU при зростанні навантаження.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
1. Що ми налаштовуємо і навіщо: Еволюція Self-hosted AI
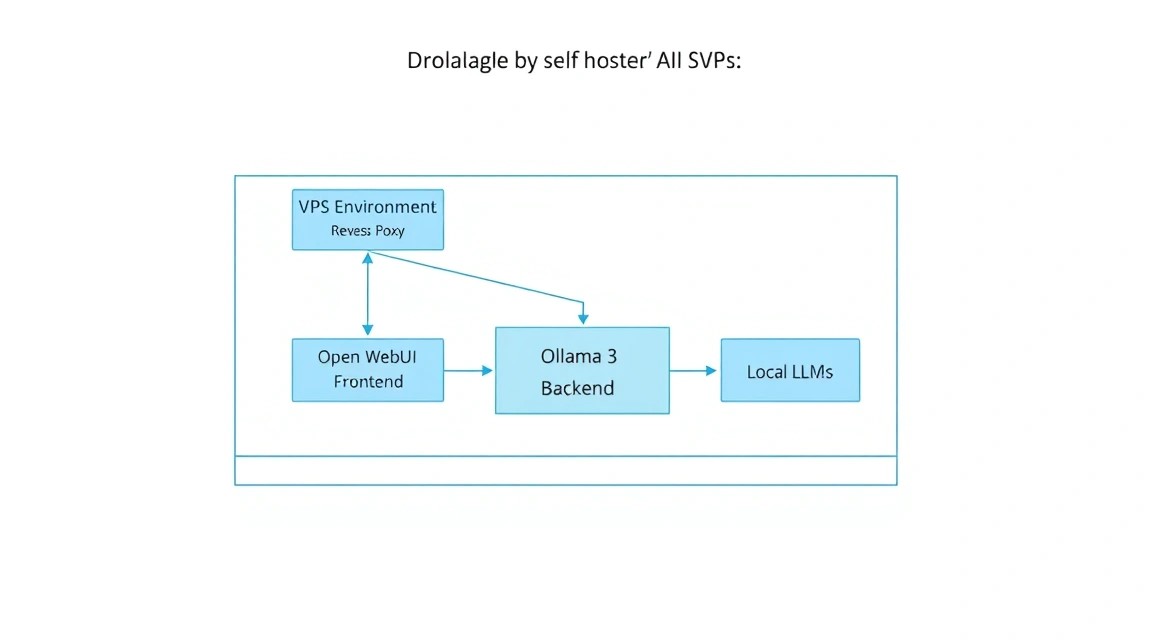 Схема: 1. Що ми налаштовуємо і навіщо: Еволюція Self-hosted AI
Схема: 1. Що ми налаштовуємо і навіщо: Еволюція Self-hosted AI
До 2026 року індустрія великих мовних моделей (LLM) розділилася на два чіткі табори: пропрієтарні хмарні рішення (OpenAI, Anthropic, Google) та відкриті моделі (Meta, Mistral AI, DeepSeek). Незважаючи на зручність перших, професійні розробники та компанії все частіше обирають self-hosted шлях. Основна причина — суверенітет даних. Коли ви використовуєте хмарний чат, кожне ваше слово стає частиною навчальної вибірки або зберігається в логах, доступних третім особам.
Ми будемо використовувати зв'язку з двох потужних інструментів:
- Ollama: Це ефективний рушій (інференс-сервер), який бере на себе всю важку роботу із завантаження ваг моделей, управління пам'яттю та виконання обчислень. Він оптимізований для роботи як на GPU, так і на CPU, використовуючи сучасні набори інструкцій (AVX-512, AMX).
- Open WebUI: Раніше відомий як Ollama WebUI, це найпросунутіший інтерфейс для роботи з локальними моделями. Він підтримує мультимодальність (аналіз зображень), RAG (Retrieval Augmented Generation — спілкування з вашими PDF/документами), управління користувачами та інтеграцію з веб-пошуком.
Self-hosted рішення на VPS дає вам незалежність від API-ключів, лімітів на кількість повідомлень на годину та "лоботомії" моделей, коли розробники надмірно обмежують відповіді ШІ з міркувань безпеки. Ваш сервер - ваші правила.
2. Який VPS-конфіг потрібен під цю задачу: Розрахунок ресурсів
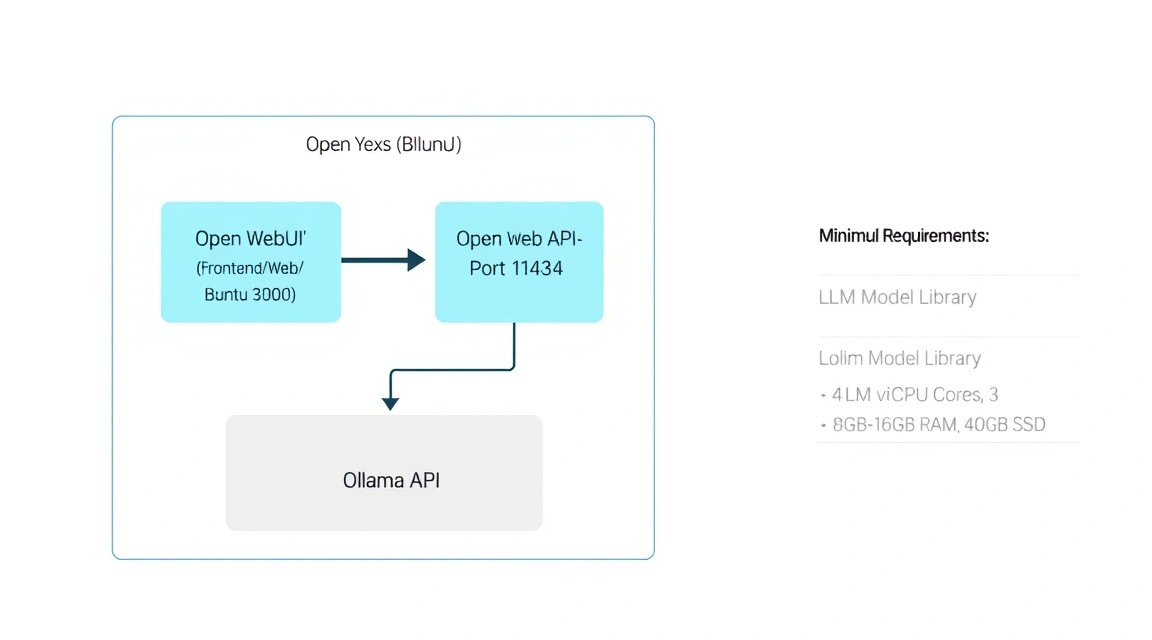 Схема: 2. Який VPS-конфіг потрібен під цю задачу: Розрахунок ресурсів
Схема: 2. Який VPS-конфіг потрібен під цю задачу: Розрахунок ресурсів
Вибір характеристик сервера безпосередньо залежить від того, які моделі ви плануєте запускати. У 2026 році стандартом для "розумного" чату є моделі з 7-14 мільярдами параметрів (7B-14B), квантовані до 4 або 8 біт.
| Тип задачі |
Модель (приклад) |
Мінімальна RAM |
Рекомендований CPU |
Диск (NVMe) |
| Легкий чат / Код |
Llama 3.2 3B / Phi-4 |
8 GB |
4 Cores |
40 GB |
| Універсальний ШІ |
Llama 3.1 8B / Mistral 7B |
16 GB |
8 Cores |
80 GB |
| Складна аналітика |
Gemma 2 27B / Command R |
32-48 GB |
12+ Cores |
160 GB |
| Enterprise / RAG |
Llama 3.1 70B (Q4) |
64 GB+ |
16+ Cores |
300 GB |
Важливо розуміти різницю між CPU та GPU інференсом. На звичайному VPS ви будете використовувати CPU. Завдяки бібліотеці llama.cpp, на якій базується Ollama, швидкість генерації на сучасних серверних процесорах досягає 3-7 токенів на секунду для моделей 8B, що цілком комфортно для читання людиною в реальному часі. Якщо ж вам потрібна миттєва генерація або обслуговування 10+ одночасних користувачів, варто розглянути виділений сервер з GPU (NVIDIA A2000, A4000 або H100/L40).
Для комфортної роботи з моделями середнього рівня (8B-14B) можна орендувати відповідний VPS з 16 ГБ оперативної пам'яті та швидкими NVMe дисками, оскільки швидкість завантаження ваг моделі в пам'ять критично важлива для чуйності інтерфейсу.
Локація сервера: Оскільки ви будете передавати та отримувати значні обсяги текстових даних, вибирайте локацію з мінімальним пінгом до вас. Однак для AI-задач важливіша фізична продуктивність процесора, ніж затримка мережі в 20-30 мс.
3. Підготовка сервера: Безпека та базове оточення
 Схема: 3. Підготовка сервера: Безпека та базове оточення
Схема: 3. Підготовка сервера: Безпека та базове оточення
Після отримання доступу до сервера через SSH, перш за все необхідно забезпечити його безпеку. AI-сервіси споживають багато ресурсів, і ви не хочете, щоб ваш сервер став частиною ботнету.
# Оновлюємо список пакетів і систему
sudo apt update && sudo apt upgrade -y
# Створюємо нового користувача з правами sudo (замініть 'aiuser' на ваше ім'я)
adduser aiuser
usermod -aG sudo aiuser
# Налаштовуємо SSH: забороняємо вхід за паролем і під користувачем root (опціонально, але рекомендовано)
# Перед цим переконайтеся, що ви додали свій SSH-ключ в ~/.ssh/authorized_keys
# sudo nano /etc/ssh/sshd_config
# Змінити: PermitRootLogin no, PasswordAuthentication no
# sudo systemctl restart ssh
Налаштування брандмауера (UFW). Нам знадобляться порти 22 (SSH), 80 (HTTP) та 443 (HTTPS). Порти Ollama (11434) і Open WebUI (8080) ми залишимо закритими від зовнішнього світу, оскільки доступ до них буде здійснюватися через реверс-проксі.
sudo ufw allow 22/tcp
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Встановлення базових утиліт, які знадобляться для моніторингу ресурсів і роботи з файлами:
sudo apt install -y curl wget git htop fastfetch build-essential
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
4. Встановлення Docker і Docker Compose (Версії 2026)
 Схема: 4. Встановлення Docker і Docker Compose (Версії 2026)
Схема: 4. Встановлення Docker і Docker Compose (Версії 2026)
Найкращий спосіб розгортання Open WebUI — використання контейнеризації. Це ізолює залежності та дозволяє легко оновлювати систему. У 2026 році Docker Compose є вбудованою частиною Docker CLI.
# Встановлення офіційного репозиторію Docker
sudo apt install -y ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Додавання репозиторію в джерела apt
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Додавання користувача в групу docker, щоб не використовувати sudo постійно
sudo usermod -aG docker $USER
# ВАЖЛИВО: Перезайдіть в SSH-сесію, щоб права оновилися
5. Розгортання Ollama: Серце вашого AI-сервера
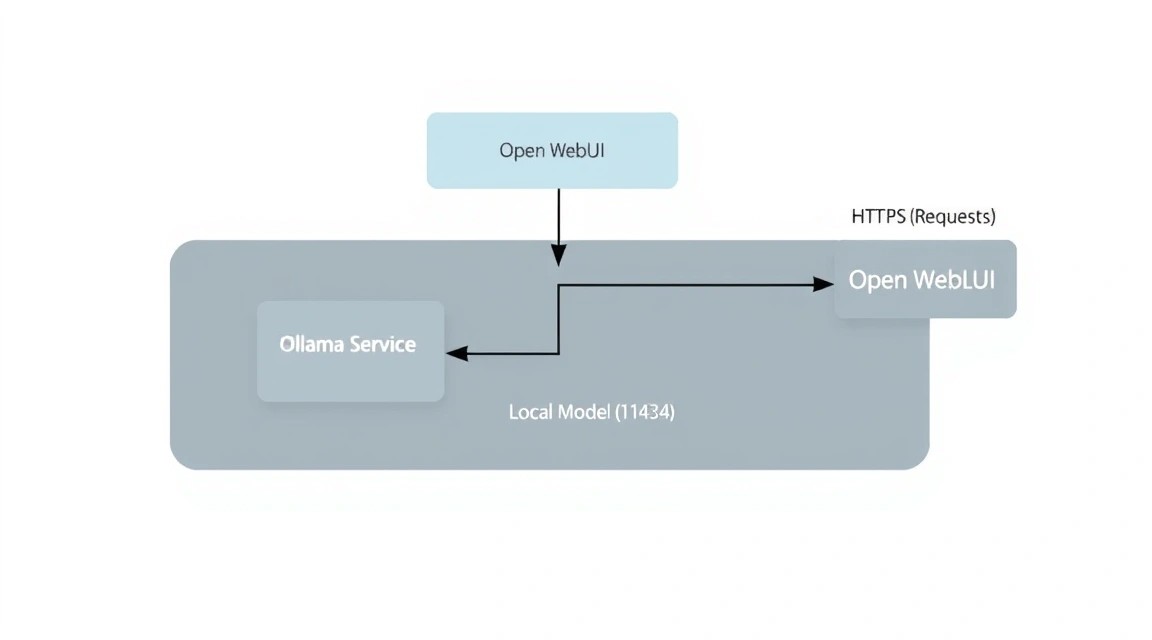 Схема: 5. Розгортання Ollama: Серце вашого AI-сервера
Схема: 5. Розгортання Ollama: Серце вашого AI-сервера
Ollama можна встановити як нативно, так і в Docker. Для максимальної продуктивності на Linux часто рекомендують нативну установку, оскільки вона має прямий доступ до інструкцій процесора без прошарків контейнеризації.
# Нативна установка Ollama однією командою
curl -fsSL https://ollama.com/install.sh | sh
Після встановлення Ollama запускається як системна служба. Перевіримо її статус:
sudo systemctl status ollama
Тепер завантажимо нашу першу модель. Llama 3.1 8B — чудовий вибір для початку. Вона збалансована за швидкістю та якістю відповідей.
ollama run llama3.1:8b
Після завершення завантаження ви зможете поспілкуватися з моделлю прямо в консолі. Для виходу введіть /bye. Модель залишиться в пам'яті сервера або буде завантажена автоматично під час першого звернення через API.
Порада: Якщо ваш сервер має обмежений обсяг RAM, використовуйте моделі з припискою :q4_k_m (4-бітове квантування), вони споживають майже вдвічі менше пам'яті при мінімальній втраті якості.
6. Встановлення Open WebUI: Інтерфейс і функціональність
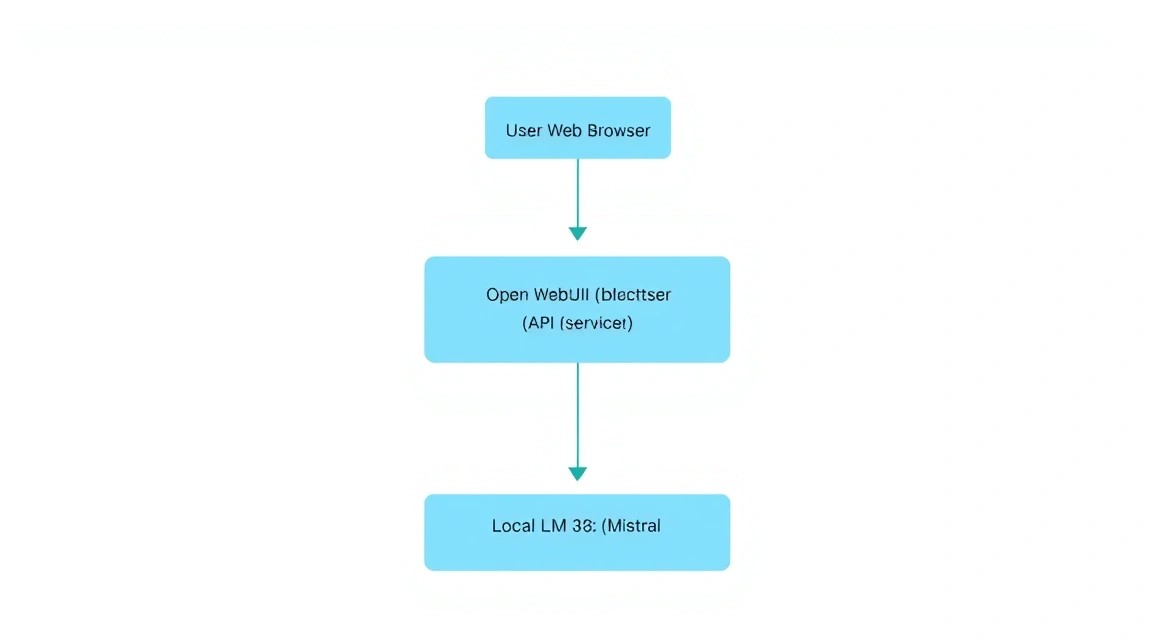 Схема: 6. Встановлення Open WebUI: Інтерфейс і функціональність
Схема: 6. Встановлення Open WebUI: Інтерфейс і функціональність
Open WebUI — це не просто чат, це повноцінна платформа. Ми розгорнемо її за допомогою Docker Compose, щоб зв'язати інтерфейс з Ollama та забезпечити зберігання даних у постійному томі (volume).
Створимо робочу директорію:
mkdir ~/ai-stack && cd ~/ai-stack
nano docker-compose.yaml
Вставте наступний вміст у файл docker-compose.yaml:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
ports:
- "8080:8080"
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- 'OLLAMA_BASE_URL=http://host.docker.internal:11434'
- 'WEBUI_SECRET_KEY=super_secret_key_change_me'
volumes:
- open-webui:/app/backend/data
volumes:
open-webui:
Розгортаємо стек:
docker compose up -d
Тепер інтерфейс доступний за адресою http://IP_ВАШОГО_СЕРВЕРА:8080. Перший зареєстрований користувач автоматично стане адміністратором.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
7. Налаштування мережі, SSL та безпеки (Caddy/Nginx)
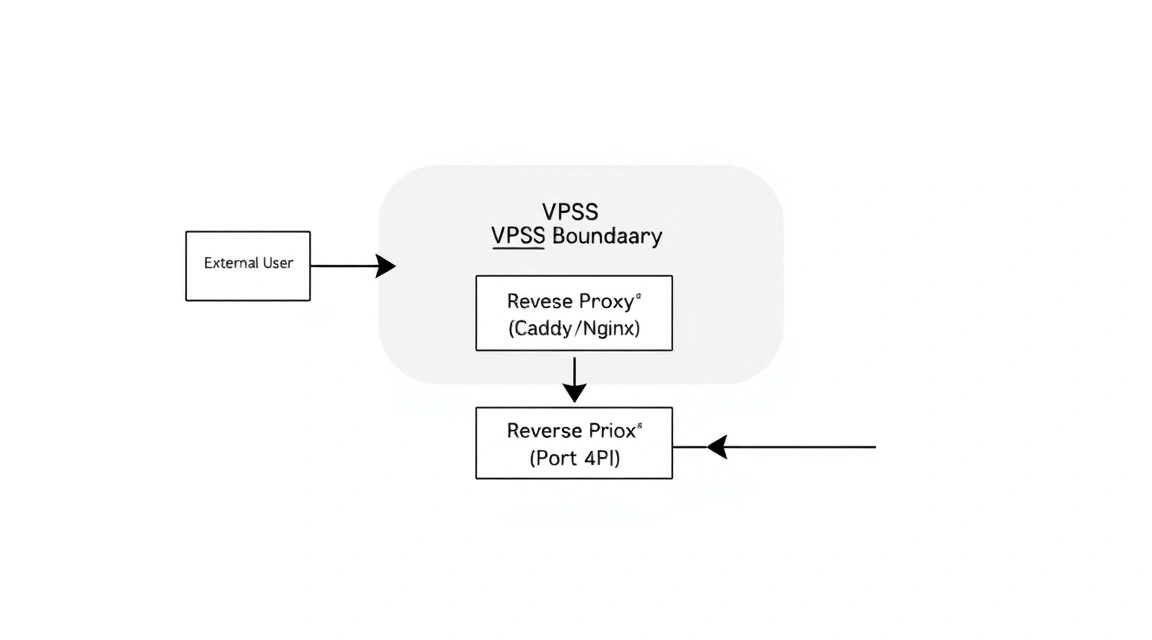 Схема: 7. Налаштування мережі, SSL та безпеки (Caddy/Nginx)
Схема: 7. Налаштування мережі, SSL та безпеки (Caddy/Nginx)
Відкривати порт 8080 напряму — погана ідея. Нам потрібен HTTPS для захисту трафіку та гарний домен. Ми будемо використовувати Caddy, оскільки він автоматично отримує та оновлює SSL-сертифікати від Let's Encrypt.
# Встановлення Caddy
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Налаштування конфігурації Caddy:
sudo nano /etc/caddy/Caddyfile
Додайте наступні рядки (замініть ai.yourdomain.com на ваш реальний домен):
ai.yourdomain.com {
reverse_proxy localhost:8080
header {
# Захист від клікджекінгу
X-Frame-Options DENY
# Захист від XSS
X-XSS-Protection "1; mode=block"
Strict-Transport-Security "max-age=31536000;"
}
}
Перезапустіть Caddy:
sudo systemctl restart caddy
Тепер ваш приватний чат доступний за безпечним протоколом HTTPS.
8. Налаштування RAG та робота з документами
Однією з найпотужніших функцій Open WebUI є RAG (Retrieval-Augmented Generation). Це дозволяє вам завантажувати PDF, текстові файли або давати посилання на сайти, щоб ШІ відповідав на питання, ґрунтуючись на цій інформації.
У 2026 році Open WebUI за замовчуванням включає в себе векторну базу даних (ChromaDB або аналогічну). Щоб RAG працював ефективно на VPS:
- Вибір Embedding-моделі: Перейдіть у налаштування адміністратора -> Documents. За замовчуванням використовується
sentence-transformers, яка добре працює на CPU.
- Завантаження документів: У вікні чату натисніть на іконку "+" або просто перетягніть файл.
- Використання: Введіть символ
# в рядку повідомлення, щоб вибрати завантажений документ для контексту.
Це перетворює ваш VPS на персональну базу знань. Ви можете завантажити документацію по проєкту, юридичні договори або підручники, і задавати питання щодо їх змісту без ризику витоку цих документів в публічні хмари.
9. Бекапи, оновлення моделей та обслуговування системи
 Схема: 9. Бекапи, оновлення моделей та обслуговування системи
Схема: 9. Бекапи, оновлення моделей та обслуговування системи
Сервер з AI потребує регулярного обслуговування, оскільки моделі та софт оновлюються майже кожного тижня.
Оновлення компонентів
# Оновлення Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Оновлення Open WebUI
cd ~/ai-stack
docker compose pull
docker compose up -d --remove-orphans
Скрипт резервного копіювання
Найважливіше — це база даних користувачів та їх чатів. В Open WebUI вона зберігається в Docker volume. Створимо простий скрипт бекапу:
#!/bin/bash
BACKUP_DIR="/home/aiuser/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
# Зупинка контейнера для консистентності даних
docker stop open-webui
# Створення архіву даних
tar -czf $BACKUP_DIR/webui_data_$TIMESTAMP.tar.gz -C /var/lib/docker/volumes/ai-stack_open-webui/_data .
# Запуск контейнера
docker start open-webui
# Видалення бекапів старше 30 днів
find $BACKUP_DIR -type f -mtime +30 -name "*.gz" -delete
Додайте цей скрипт в crontab -e для щоденного запуску о 3 годині ночі.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
10. Troubleshooting + FAQ: Розв'язання типових проблем
Чому генерація тексту йде дуже повільно?
Основна причина — нестача оперативної пам'яті. Якщо моделі не вистачає RAM, система починає використовувати swap (підкачку на диску), що сповільнює роботу в сотні разів. Перевірте споживання пам'яті командою htop. Також переконайтеся, що ви не запускаєте модель, розмір якої перевищує доступну RAM. Для моделі 8B потрібно мінімум 8-10 ГБ вільної пам'яті.
Помилка "Connection refused" при підключенні WebUI до Ollama
Перевірте, чи слухає Ollama порт 11434 на всіх інтерфейсах. За замовчуванням вона може слухати тільки 127.0.0.1. В Docker-compose ми використовували host.docker.internal, що правильно для зв'язку контейнера з хостом. Переконайтеся, що змінна оточення OLLAMA_HOST=0.0.0.0 встановлена в системі, якщо використовуєте складну мережеву конфігурацію.
Який VPS-конфіг мінімально підійде?
Для запуску найменших моделей на кшталт Phi-3 або Llama 3.2 3B достатньо 4-8 ГБ RAM та 2-4 ядер CPU. Однак для повноцінного досвіду з моделями рівня Llama 3.1 8B ми наполегливо рекомендуємо 16 ГБ RAM. Це забезпечить запас для роботи ОС, Docker та кешування контексту.
Що вибрати — VPS чи dedicated для цієї задачі?
VPS ідеально підходить для особистого використання та експериментів. Якщо ж ви плануєте впроваджувати AI в бізнес-процеси компанії, де чатом будуть користуватися 20+ співробітників одночасно, або вам потрібно навчати моделі (fine-tuning), однозначно варто вибрати виділений сервер (dedicated) з потужним багатоядерним процесором або GPU.
Як обмежити доступ до чату?
В налаштуваннях Open WebUI (Admin Settings -> General) можна відключити "New Signups". Після того як ви створите акаунти для себе та своєї команди, вимкніть реєстрацію, щоб сторонні не могли використовувати ресурси вашого сервера.
Чи можу я використовувати GPU на VPS?
Так, якщо провайдер надає GPU-прискорення та прокидання пристрою у віртуальну машину. В цьому випадку вам потрібно буде встановити nvidia-container-toolkit та додати deploy.resources.reservations.devices у ваш docker-compose.yaml. Швидкість генерації виросте в 10-50 разів.
11. Висновки та наступні кроки: Шлях до персонального агента
Ми успішно розгорнули повністю приватне та функціональне середовище штучного інтелекту. Тепер у вас є власний аналог ChatGPT, який не піддається цензурі, не торгує вашими даними та доступний вам 24/7 за фіксованою ціною оренди сервера.
Куди рухатися далі?
- Інтеграція з API: Використовуйте адресу вашого сервера в якості заміни OpenAI API в таких додатках, як Cursor або Obsidian.
- Кастомні моделі: Спробуйте спеціалізовані моделі для програмування (CodeLlama, DeepSeek-Coder) або медичні/юридичні моделі.
- Автоматизація: Налаштуйте інтеграцію з вашим календарем або поштою через API Open WebUI, перетворюючи чат на повноцінного цифрового асистента.
Пам'ятайте, що сфера локальних LLM розвивається стрімко. Слідкуйте за оновленнями Ollama та Open WebUI, оскільки нові версії часто приносять значні оптимізації швидкості, дозволяючи запускати все більш складні моделі на тому ж залізі.