Як зробити резервне копіювання з дедуплікацією?
Зробити резервне копіювання з дедуплікацією можна кількома способами: використовуючи спеціалізоване програмне забезпечення на кшталт BorgBackup або Veeam, задіюючи вбудовані функції файлових систем (наприклад, ZFS або Btrfs на Linux, Data Deduplication на Windows Server) або застосовуючи мережеві сховища (NAS/SAN) з апаратною або програмною підтримкою дедуплікації. Головна мета — значно скоротити обсяг збережених даних, зменшити час копіювання та знизити витрати на зберігання за рахунок виключення дублікатів на рівні файлів або блоків.
Колеги, напевно кожен з вас стикався з тим, що обсяги даних ростуть, як на дріжджах. Бази даних, логи, віртуальні машини, файли користувачів — все це вимагає регулярного бекапу. Але чим більше даних, тим довше процес копіювання, тим більше місця потрібно на бекап-сховище, і тим вищі підсумкові витрати. Тут на допомогу приходить дедуплікація — технологія, яка дозволяє ефективно боротися з надмірністю даних, значно скорочуючи їх обсяг. Давайте розберемося, як це працює і які інструменти у нас є в арсеналі.
Що таке дедуплікація і навіщо вона потрібна?
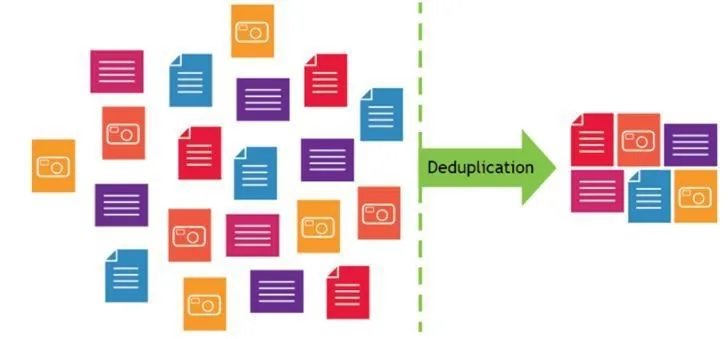
Дедуплікація даних — це процес виявлення та усунення надлишкових копій даних. Замість того щоб зберігати кілька ідентичних копій одного і того ж файлу або блоку даних, система зберігає тільки одну унікальну копію, а всі інші замінюються посиланнями або вказівниками на цю єдину копію. Це схоже на хардлінки у файловій системі, але на набагато більш гранулярному рівні.
Чому дедуплікація критично важлива для бекапів?
- Економія місця: Це найбільш очевидна і значна вигода. Особливо актуально для інкрементальних або диференціальних бекапів, де зміни часто стосуються лише невеликих частин файлів, а більша частина даних залишається незмінною між знімками.
- Скорочення часу бекапу: Менше даних для копіювання означає швидше завершення процесу, що критично для виконання RTO/RPO.
- Зниження навантаження на мережу: При віддаленому бекапуванні дедуплікація значно зменшує обсяг переданих даних, економлячи пропускну здатність.
- Зменшення витрат: Менше місця на дисках, менше трафіку — все це веде до зниження операційних витрат.
Види дедуплікації
Дедуплікація може бути реалізована на різних рівнях і в різних місцях:
- Файлова дедуплікація: Найпростіший вид. Система порівнює хеші файлів і, якщо вони збігаються, зберігає тільки одну копію. Ефективна для ідентичних файлів, але не допомагає, якщо змінився навіть один байт.
- Блокова дедуплікація: Більш просунутий підхід. Дані розбиваються на блоки (фіксованого або змінного розміру). Система порівнює хеші цих блоків. Якщо блок вже існує, зберігається тільки посилання. Це набагато ефективніше, так як зміни в одному файлі зазвичай зачіпають лише невелику кількість блоків.
- Source-side (клієнтська) дедуплікація: Процес дедуплікації відбувається на сервері, який відправляє дані для бекапу. Це знижує навантаження на мережу, так як передаються тільки унікальні блоки.
- Target-side (цільова) дедуплікація: Дані передаються на бекап-сховище в повному обсязі, і вже там відбувається процес дедуплікації. Вимагає більше пропускної здатності мережі, але знімає навантаження з сервера, що бекапірується.
Для наочності, ось невелика таблиця порівняння ключових характеристик:
| Характеристика | Файлова дедуплікація | Блокова дедуплікація |
|---|---|---|
| Гранулярність | Весь файл | Блоки даних (4KB, 8KB, 16KB і т.д.) |
| Ефективність | Менше, тільки для ідентичних файлів | Вище, навіть при невеликих змінах у файлах |
| Навантаження на CPU/RAM | Нижче | Вище |
| Приклади | rsync --link-dest, деякі прості системи |
BorgBackup, Restic, ZFS, Windows Data Deduplication, Veeam |
Способи реалізації дедуплікації в резервному копіюванні
Тепер, коли ми розуміємо основи, давайте розглянемо конкретні методи та інструменти, доступні системним адміністраторам.
1. Спеціалізоване програмне забезпечення
Це найпоширеніший і гнучкий підхід. Існує безліч рішень, як пропрієтарних, так і з відкритим вихідним кодом, які пропонують потужні функції дедуплікації.
Пропрієтарні рішення
- Veeam Backup & Replication: Лідер в області бекапу віртуальних машин. Veeam пропонує блокову дедуплікацію і компресію, значно скорочуючи розмір бекапів VM. Він також підтримує source-side дедуплікацію для зменшення мережевого трафіку. Ідеально підходить для віртуалізованих середовищ.
- Commvault, Rubrik, Cohesity: Комплексні корпоративні рішення для управління даними, які включають в себе просунуті механізми дедуплікації, часто інтегровані з апаратними платформами.
- Proxmox Backup Server (PBS): Відмінне рішення для тих, хто працює з Proxmox VE. PBS надає ефективну блокову дедуплікацію, компресію, шифрування і перевірку цілісності даних. Він спеціально розроблений для бекапу віртуальних машин і контейнерів Proxmox.
Open-Source і CLI-інструменти (наш вибір для VPS/серверів)
Для серверів і VPS, де важлива гнучкість, мінімалізм і контроль, командні утиліти з відкритим вихідним кодом часто є кращим вибором.
-
BorgBackup (Borg): Один з фаворитів в співтоваристві Linux. Borg надає дуже ефективну блокову дедуплікацію (зі змінним розміром блоків), компресію, шифрування (AEAD) і можливість віддаленого зберігання репозиторіїв. Він швидкий, надійний і простий у використанні для sysadmins.
«BorgBackup — це не просто інструмент для бекапу; це філософія ефективного і безпечного зберігання історії ваших даних.»
- Restic: Ще один відмінний інструмент з відкритим вихідним кодом, схожий на Borg. Restic також пропонує блокову дедуплікацію, шифрування і підтримку різних бекендів (локальні диски, S3, MinIO, SFTP і т.д.). Його сильна сторона — простота налаштування і широкий спектр підтримуваних сховищ.
- Duplicati: Кросплатформенне рішення з GUI і CLI. Підтримує інкрементальні бекапи з дедуплікацією, шифруванням і збереженням на різні хмарні і локальні сховища.
2. Вбудовані засоби операційної системи і файлових систем
Деякі операційні системи і файлові системи надають вбудовані механізми дедуплікації, які можуть бути дуже ефективними.
Windows Server Data Deduplication
Починаючи з Windows Server 2012, Microsoft пропонує вбудовану технологію Data Deduplication. Вона працює на рівні томів NTFS і дозволяє значно скоротити обсяг даних на файлових серверах, VDI-сховищах і інших робочих навантаженнях з високим ступенем надмірності.
- Як включити: Встановлюється як роль через Server Manager.
- Принцип роботи: Автоматично сканує файли, виявляє дублюються блоки і замінює їх посиланнями. Процес може виконуватися за розкладом.
- Обмеження: Не рекомендується для системних томів, томів з базами даних (SQL, Exchange), так як це може негативно позначитися на продуктивності. Ідеально для файлових шарів і сховищ VDI-профілів.
ZFS і Btrfs (для Linux)
Ці сучасні файлові системи для Linux мають вбудовану підтримку дедуплікації на рівні блоків. Це потужний інструмент, але вимагає уважного підходу.
-
ZFS: Дедуплікація в ZFS (
dedup=on) працює на рівні блоків і може бути дуже ефективною. Однак вона вимагає значного обсягу оперативної пам'яті для зберігання таблиці дедуплікації (DDT - Deduplication Table). Для кожного блоку даних, що зберігається в пулі, потрібно близько 320 байт RAM. Якщо DDT не поміщається в RAM, продуктивність може сильно впасти. Тому ZFS дедуплікація рекомендується тільки при наявності великого обсягу RAM і високого ступеня надмірності даних.# Створення ZFS пулу з дедуплікацією zpool create -o ashift=12 rpool /dev/sdb zfs create -o dedup=on rpool/backup_storage -
Btrfs: Btrfs також підтримує дедуплікацію, але вона зазвичай не виконується в реальному часі. Замість цього використовуються інструменти пост-обробки, такі як
duperemoveабоbtrfs-dedup, які сканують файлову систему і видаляють дублікати. Це дозволяє уникнути накладних витрат на CPU/RAM в процесі запису.# Приклад використання duperemove для дедуплікації Btrfs duperemove -r /mnt/btrfs_volume
3. Мережеві сховища (NAS/SAN) з вбудованою дедуплікацією
Для великих інфраструктур часто використовуються спеціалізовані СЗД (системи зберігання даних), які мають вбудовані апаратні або програмні механізми дедуплікації.
Надійне дедупліцироване резервне копіювання: виберіть свій VPS-хостинг
Забезпечте безпеку ваших даних за допомогою ефективного дедупліцированого резервного копіювання. Наші VPS-плани пропонують ідеальну платформу для цього. — from €4.49/mo.
Вибрати VPS-хостинг →- Dell EMC Unity, NetApp FAS, HPE Nimble Storage: Ці корпоративні рішення пропонують дедуплікацію на рівні контролерів сховища. Вони здатні обробляти величезні обсяги даних і забезпечувати високу продуктивність.
- Принцип роботи: Зазвичай це target-side блокова дедуплікація, яка відбувається вже на самому сховищі. Це дозволяє розвантажити сервери-джерела і використовувати оптимізоване апаратне забезпечення СЗД для виконання ресурсоємних операцій.
- Інтеграція: Такі СЗД часто інтегруються з популярними бекап-системами, надаючи API для більш ефективної взаємодії.
Практичні рекомендації по впровадженню
Незалежно від обраного методу, є кілька ключових моментів, які варто враховувати при впровадженні дедуплікації у вашу стратегію резервного копіювання:
- Розуміння ваших даних: Оцініть ступінь надмірності. Бази даних з постійними змінами або зашифровані дані гірше дедуплікуються, ніж файлові сервери або образи VM.
- Продуктивність: Дедуплікація — ресурсоємний процес. Переконайтеся, що у вас достатньо CPU і RAM на стороні, де вона виконується (клієнт або сховище).
- Перевірка цілісності: Переконайтеся, що обране рішення використовує хешування і механізми перевірки цілісності даних. Помилка в одному блоці може пошкодити безліч файлів, якщо вони посилаються на нього.
- Тестування відновлення: Як і з будь-яким бекапом, регулярне тестування відновлення даних критично важливо. Переконайтеся, що дедупліцировані дані відновлюються коректно і в прийнятні терміни.
- Розмір блоків: Деякі системи дозволяють налаштовувати розмір блоків дедуплікації. Менші блоки дають кращу ступінь дедуплікації, але вимагають більше ресурсів; великі блоки — навпаки.
- Шифрування: Завжди використовуйте шифрування для бекапів, особливо якщо вони зберігаються поза вашої мережі. Деякі методи шифрування можуть знижувати ефективність дедуплікації, якщо застосовуються до неї. Ідеально, якщо дедуплікація відбувається до шифрування.
Приклад: Дедупліцироване резервне копіювання з BorgBackup
Давайте розглянемо швидкий приклад використання BorgBackup для створення дедупліцированих бекапів на Linux-сервері. Ми будемо виконувати бекап директорії /var/www/html і /etc на віддалений сервер через SSH.
1. Установка BorgBackup
На сервері, який потрібно бекапіти, і на сервері, де буде зберігатися репозиторій:
# Debian/Ubuntu
sudo apt update
sudo apt install borgbackupДедуплікація в резервному копіюванні: економія місця та підвищення ефективності
Дедуплікація (також відома як дедублікація або dedupe) - це метод стиснення даних, який усуває повторювані копії даних. Замість зберігання кількох однакових копій даних, зберігається тільки одна унікальна копія, а інші замінюються посиланнями на неї. Це може значно зменшити обсяг необхідного дискового простору для зберігання резервних копій, особливо коли йдеться про великі обсяги даних.
Як працює дедуплікація?
Процес дедуплікації зазвичай складається з наступних кроків:
- Розбиття даних на блоки: Дані розбиваються на невеликі блоки фіксованого або змінного розміру.
- Обчислення хешів: Для кожного блоку обчислюється хеш (унікальний ідентифікатор).
- Порівняння хешів: Обчислені хеші порівнюються з хешами вже збережених блоків.
- Збереження унікальних блоків: Якщо хеш нового блоку не знайдено в базі даних, блок зберігається, а його хеш додається до бази даних.
- Заміна дублікатів посиланнями: Якщо хеш нового блоку знайдено, замість зберігання самого блоку створюється посилання на вже збережений блок.
Типи дедуплікації
- Дедуплікація на рівні файлів (File-level deduplication): Зберігає тільки одну копію кожного файлу, замінюючи дублікати посиланнями. Ефективна для невеликої кількості файлів великого розміру.
- Дедуплікація на рівні блоків (Block-level deduplication): Розбиває файли на блоки і зберігає тільки унікальні блоки. Більш ефективна, ніж дедуплікація на рівні файлів, особливо при великій кількості дрібних змін у файлах.
- Дедуплікація на рівні змінних блоків (Variable-length block deduplication): Визначає розмір блоків динамічно, що дозволяє більш ефективно знаходити дублікати, навіть якщо дані були змінені.
- Дедуплікація "in-line" (In-line deduplication): Дедуплікація відбувається в режимі реального часу під час запису даних.
- Дедуплікація "post-process" (Post-process deduplication): Дедуплікація відбувається після запису даних, в окремий час.
Переваги дедуплікації
- Економія дискового простору: Значне зменшення обсягу необхідного дискового простору для зберігання резервних копій.
- Зменшення витрат на зберігання: Зменшення витрат на придбання та обслуговування дискового простору.
- Прискорення резервного копіювання: Зменшення обсягу даних, що передаються, що призводить до прискорення процесу резервного копіювання.
- Зменшення навантаження на мережу: Зменшення обсягу даних, що передаються по мережі, що зменшує навантаження на мережу.
Інструменти для дедуплікації
Існує безліч інструментів для дедуплікації, як комерційних, так і з відкритим вихідним кодом. Ось деякі з них:
- Veeam Backup & Replication: Комплексне рішення для резервного копіювання та відновлення віртуальних машин VMware vSphere та Microsoft Hyper-V з вбудованою дедуплікацією.
- Proxmox Backup Server: Рішення з відкритим вихідним кодом для резервного копіювання віртуальних машин та контейнерів Proxmox VE з вбудованою дедуплікацією.
- BorgBackup: Вільний, безпечний та ефективний дедуплікуючий архіватор.
- Restic: Швидка, безпечна та проста програма для резервного копіювання, яка підтримує дедуплікацію.
- Windows Server Data Deduplication: Вбудована функція дедуплікації в Windows Server для оптимізації дискового простору на файлових серверах.
Приклад використання BorgBackup для резервного копіювання Linux-сервера
BorgBackup - це потужний інструмент для створення резервних копій Linux-систем з підтримкою дедуплікації та шифрування. Ось приклад налаштування BorgBackup для резервного копіювання Linux-сервера на віддалений сервер.
1. Встановлення BorgBackup
Спочатку встановіть BorgBackup на обох серверах (вихідному та віддаленому). Для CentOS/RHEL:
# CentOS/RHEL
sudo yum install epel-release
sudo yum install borgbackup2. Підготовка репозиторію на віддаленому сервері
На віддаленому сервері створіть користувача для бекапів та директорію для репозиторію. Припустимо, користувач borguser та директорія /backups/my_server.
# На віддаленому сервері
sudo adduser borguser
sudo mkdir -p /backups/my_server
sudo chown borguser:borguser /backups/my_server
# Додайте SSH-ключ користувача бекапа з вихідного сервера в authorized_keys borguser3. Ініціалізація репозиторію на вихідному сервері
З вихідного сервера ініціалізуйте репозиторій. Використовуйте --encryption=repokey-blake2 для шифрування репозиторію за допомогою пароля (рекомендується).
# На вихідному сервері
borg init --encryption=repokey-blake2 ssh://borguser@remote_server_ip:/backups/my_server
# Вас попросять ввести і підтвердити пароль для репозиторію. Запам'ятайте його!4. Створення першого бекапа
Тепер створимо перший архів. ::my_server-{now} створює ім'я архіву з поточною датою та часом.
# На вихідному сервері
borg create --stats --progress \
ssh://borguser@remote_server_ip:/backups/my_server::my_server-{now} \
/var/www/html \
/etc \
/home/user/documents
# Введіть пароль репозиторію, коли попросить.Флаги --stats та --progress покажуть вам статистику дедуплікації та прогрес.
5. Створення наступних бекапів
Всі наступні бекапи будуть використовувати дедуплікацію. Borg буде передавати тільки унікальні блоки даних.
# На вихідному сервері
borg create --stats --progress \
ssh://borguser@remote_server_ip:/backups/my_server::my_server-{now} \
/var/www/html \
/etc \
/home/user/documents6. Перегляд архівів та дедуплікації
# На вихідному сервері
borg list ssh://borguser@remote_server_ip:/backups/my_server
borg info ssh://borguser@remote_server_ip:/backups/my_server::my_server_archive_name
# Ви побачите статистику по дедуплікації: Original size, Compressed size, Deduplicated size.7. Видалення старих архівів (Pruning)
Для економії місця та управління життєвим циклом бекапів використовуйте команду prune.
# На вихідному сервері: зберігати 7 останніх щоденних, 4 останніх щотижневих, 6 останніх щомісячних
borg prune -v --list \
ssh://borguser@remote_server_ip:/backups/my_server \
--keep-daily=7 --keep-weekly=4 --keep-monthly=6Це лише базовий приклад. BorgBackup пропонує набагато більше можливостей, включаючи перевірку цілісності, монтування архівів як файлових систем та багато іншого.
Висновки
Дедуплікація — це не просто модне слово, а потужний інструмент в арсеналі кожного системного адміністратора. Вона дозволяє ефективно управляти зростаючими обсягами даних, значно скорочуючи витрати на зберігання та прискорюючи процеси резервного копіювання. Вибір конкретного методу залежить від вашої інфраструктури: для віртуальних машин чудово підійде Veeam або Proxmox Backup Server, для Linux-серверів незамінні BorgBackup та Restic, а для Windows-серверів з файловими шарами — вбудована Data Deduplication. Корпоративні СЗД пропонують свої рішення для великих обсягів. Головне — ретельно спланувати стратегію, протестувати обране рішення та регулярно перевіряти цілісність ваших бекапів. Адже який толк від зекономленого місця, якщо відновити дані неможливо?
Сподіваємось, ця стаття допомогла вам розібратися в нюансах дедуплікації та обрати оптимальний шлях для вашої інфраструктури. Успішних бекапів, колеги!