Привіт, колеги-сисадміни!
Як перевірити навантаження на гіпервізор? Це одне з ключових питань у роботі будь-кого, хто керує віртуальною інфраструктурою. Щоб відповісти на нього прямо: перевірка навантаження на гіпервізор — це комплексний процес, який включає в себе моніторинг основних системних ресурсів (CPU, RAM, I/O диска, мережа) як на рівні самого гіпервізора, так і всередині гостьових віртуальних машин, використовуючи комбінацію вбудованих інструментів гіпервізора, CLI-утиліт і централізованих систем моніторингу. Мета — виявити потенційні вузькі місця, запобігти деградації продуктивності та забезпечити стабільну роботу всього віртуалізованого середовища.
Чому моніторинг навантаження на гіпервізор критично важливий?
Гіпервізор — це серце вашої віртуальної інфраструктури. Він розподіляє фізичні ресурси між усіма запущеними віртуальними машинами. Якщо гіпервізор перевантажений, це миттєво позначається на продуктивності всіх ВМ, що призводить до затримок, зниження відгуку програм і, в кінцевому підсумку, до невдоволення користувачів або навіть простоїв. Регулярний і глибокий аналіз навантаження дозволяє:
- Проактивно виявляти проблеми: Помітити тенденції до зростання навантаження до того, як вони стануть критичними.
- Оптимізувати ресурси: Правильно розподіляти CPU, RAM і I/O між ВМ.
- Планувати ємність: Розуміти, скільки ще ВМ можна запустити на поточному обладнанні або коли знадобиться апгрейд.
- Усувати неполадки: Швидко локалізувати причину деградації продуктивності.
- Забезпечувати SLA: Гарантувати заявлений рівень сервісу для програм і користувачів.
Основні метрики для моніторингу
Щоб отримати повну картину, необхідно відстежувати кілька ключових показників. Важливо розуміти, що ми дивимося на використання ресурсів з точки зору самого гіпервізора, а не тільки зсередини гостьової ОС.
1. Центральний процесор (CPU)
CPU — одне з найчастіших джерел вузьких місць. На гіпервізорі важливо відстежувати не тільки загальне використання CPU, але і його розподіл.
- Загальне завантаження CPU: Відсоток використання всіх доступних ядер/потоків. Високі значення (наприклад, постійно вище 80-90%) вказують на брак ресурсів.
- CPU Ready Time (для VMware), CPU Wait Time (для KVM/Xen): Це час, який віртуальна машина чекає, поки гіпервізор виділить їй фізичні ядра. Високі значення (наприклад, понад 5-10% від загального часу ВМ) означають CPU-контенцію, тобто ВМ хоче працювати, але немає вільних фізичних ядер. Це один з найнадійніших індикаторів перевантаження CPU на гіпервізорі.
- Використання CPU гіпервізором: Відсоток CPU, який сам гіпервізор використовує для своїх потреб (управління ВМ, планувальник, драйвери).
- Використання CPU гостьовими ВМ: Сумарне використання CPU всіма ВМ.
2. Оперативна пам'ять (RAM)
Брак пам'яті призводить до свопінгу, що різко сповільнює систему.
- Загальне використання RAM: Скільки фізичної пам'яті використовується.
- Доступна RAM: Скільки вільної пам'яті залишилося на гіпервізорі.
- Memory Ballooning/Swapping: Механізми, які гіпервізор використовує для "відбирання" пам'яті у ВМ, коли її не вистачає. Активний ballooning або, що гірше, свопінг на диски гіпервізора, — чіткий сигнал про брак пам'яті.
- Memory Overhead: Пам'ять, що використовується самим гіпервізором для управління кожною ВМ.
3. Дисковий ввід/вивід (I/O)
Продуктивність дискової підсистеми часто стає пляшковим горлечком, особливо в середовищах з безліччю ВМ, що активно працюють з дисками.
- IOPS (Input/Output Operations Per Second): Кількість операцій читання/запису в секунду.
- Пропускна здатність (Throughput): Обсяг даних, що передаються на диск/з диска в секунду (MB/s).
- Латентність (Latency): Час відгуку дискової підсистеми. Висока латентність (наприклад, десятки мілісекунд) — головний індикатор проблем з дисками.
- Довжина черги (Queue Depth): Кількість очікуючих I/O-операцій. Високе значення вказує на перевантаження.
4. Мережа
Мережева підсистема може бути перевантажена, якщо ВМ активно обмінюються даними.
Потрібен максимальний контроль над продуктивністю вашого гіпервізора?
Для критично важливих робочих навантажень, де кожна мілісекунда має значення, виділений сервер пропонує неперевершену продуктивність і безпеку. Отримайте повний контроль над вашою інфраструктурою. — from €5.99/mo.
Вибрати сервер →- Пропускна здатність: Обсяг вхідного/вихідного трафіку (Mbps/Gbps).
- Кількість пакетів в секунду (PPS): Може бути важливіше пропускної здатності для деяких типів навантажень.
- Помилки/відкинуті пакети: Індикатори проблем на мережевому рівні.
Інструменти для перевірки навантаження
Для моніторингу можна використовувати як вбудовані засоби гіпервізора, так і універсальні утиліти.
1. Інструменти командного рядка (CLI)
Ці утиліти незамінні для швидкої діагностики та глибокого аналізу безпосередньо на хості гіпервізора (особливо для Linux-основаних, таких як KVM, Proxmox, Xen).
-
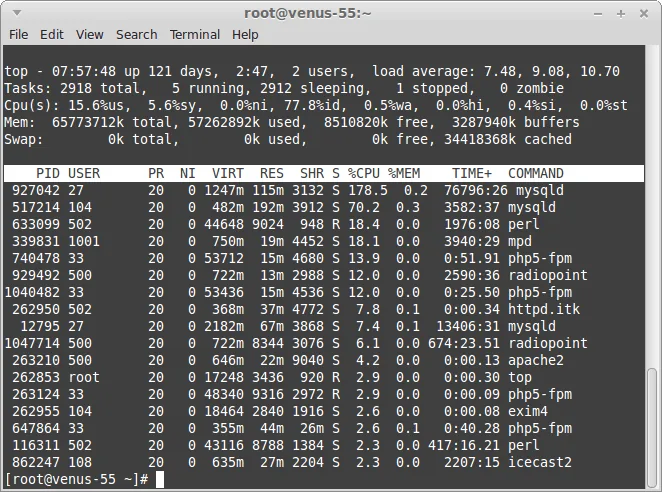
top/htop: Загальна картина використання CPU і RAM, список процесів. На гіпервізорі покаже використання ресурсів самим гіпервізором і процесами, пов'язаними з ВМ (наприклад, qemu-kvm).top -d 2 -
vmstat: Статистика віртуальної пам'яті, CPU, дискового I/O. Корисно для виявлення свопінгу і CPU wait.vmstat 2 10Зверніть увагу на стовпці
wa(wait I/O) іsi/so(swap in/out). -
iostat: Детальна статистика дискового I/O (IOPS, пропускна здатність, латентність).iostat -x -k 2Дивіться на
%util(завантаження диска),await(середній час очікування I/O-операції) іsvctm(середній час обслуговування). -
netstat/ss: Мережева статистика, відкриті з'єднання, помилки.netstat -s -t -u -
sar(System Activity Reporter): Потужний інструмент для збору і аналізу історії системних активностей (CPU, пам'ять, I/O, мережа). Потребує встановлення пакетаsysstat.sar -u 2 5 # CPU usage sar -r 2 5 # Memory usage sar -b 2 5 # I/O transfer rate -
virsh dominfo <VM_NAME>/virsh cpu-stats <VM_NAME>(для KVM): Дозволяє отримати інформацію про конкретну ВМ, включаючи використання CPU.
2. Інструменти управління гіпервізорами і GUI
Більшість гіпервізорів надають свої власні засоби моніторингу, які дають агреговану і зручну для сприйняття інформацію.
-
VMware vCenter/ESXi Host Client: Надає докладні графіки продуктивності для CPU (включаючи Ready Time), RAM (включаючи Ballooning), дискового I/O (Latency, IOPS) і мережі на рівні хоста і окремих ВМ. Це основний інструмент для VMware.
Де дивитися: У vCenter Server, виберіть хост, потім вкладка "Monitor" -> "Performance" -> "Advanced".
-
Proxmox VE Web Interface: Інформативна панель моніторингу з графіками по CPU, RAM, дискам і мережі для всього хоста і кожної ВМ. Показує load average, використання пам'яті, I/O-статистику.
Де дивитися: У веб-інтерфейсі Proxmox, виберіть ноду або ВМ, вкладка "Summary" або "Metrics".
-
Microsoft Hyper-V Manager / Windows Admin Center: Дозволяє переглядати базові метрики використання CPU, RAM, дисків для хоста і ВМ. Для більш глибокого аналізу на Hyper-V хості можна використовувати "Performance Monitor" Windows.
Де дивитися: У Hyper-V Manager, виберіть хост, потім "Performance".
-
XenCenter / XCP-ng Center: Надає графіки використання ресурсів для хостів і ВМ в середовищі XenServer/XCP-ng.
3. Централізовані системи моніторингу
Для великих інфраструктур незамінні системи, які збирають метрики з усіх гіпервізорів і ВМ, агрегують їх і дозволяють будувати кастомні дашборди і налаштовувати оповіщення.
-
Prometheus + Grafana: Потужна зв'язка. Prometheus збирає метрики (через Node Exporter для хостів, vSphere Exporter для VMware, Telegraf для KVM/Xen) і зберігає їх. Grafana візуалізує дані, дозволяючи створювати інтерактивні дашборди. Ідеально для глибокого аналізу і трендів.
Приклад запиту PromQL для CPU Ready Time (VMware):
sum by (vmname) (vmware_vm_cpu_ready_average_milliseconds_total[5m]) / 300000 * 100Це покаже середній відсоток CPU Ready Time за 5 хвилин.
-
Zabbix: Комплексна система моніторингу, що підтримує агенти (для хостів) і спеціальні шаблони для моніторингу VMware vCenter/ESXi, Hyper-V, KVM. Дозволяє налаштовувати складні тригери і оповіщення.
-
Nagios / Icinga: Класичні системи моніторингу, які можна налаштувати для перевірки стану гіпервізорів і їх ресурсів.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інтерпретація даних і пошук вузьких місць
Просто бачити цифри недостатньо, потрібно вміти їх інтерпретувати.
-
Встановіть базові лінії: Поспостерігайте за системою протягом деякого часу в нормальному режимі роботи, щоб зрозуміти, які значення метрик є типовими для вашого середовища. Будь-які значні відхилення від цієї бази можуть вказувати на проблему.
-
Шукайте кореляції: Якщо CPU Ready Time високий, перевірте, чи не збігається це з піками I/O або мережевої активності. Можливо, одна ВМ з інтенсивним дисковим навантаженням "забирає" ресурси у інших, побічно впливаючи на CPU.
-
Розрізняйте проблеми гостьової ОС і гіпервізора: Якщо ВМ показує 100% CPU usage, а гіпервізор — низький CPU Ready Time для цієї ВМ, то проблема, швидше за все, всередині гостьової ОС. Якщо ж CPU Ready Time високий, то гіпервізор не встигає виділити ресурси, і це вже його проблема.
-
Моніторинг ресурсів ВМ: Не забувайте, що поведінка гостьових ОС безпосередньо впливає на гіпервізор. ВМ з "голодним" додатком може споживати надлишкові ресурси, створюючи навантаження на хост. Використовуйте інструменти всередині ВМ (Task Manager,
top,htop) для виявлення винуватців. -
Порогові значення: Визначте прийнятні порогові значення для кожної метрики. Наприклад:
- CPU Ready Time: <5% (іноді до 10% допустимо для коротких піків).
- Disk Latency: <10-20ms (для критичних додатків <5ms).
- Memory Swapping: 0 (будь-яке активне свопірування — проблема).
Кращі практики
- Регулярний аудит: Не чекайте проблем, щоб почати моніторинг. Проводьте регулярні перевірки.
- Автоматизація: Налаштуйте централізовану систему моніторингу з оповіщеннями, щоб отримувати повідомлення про проблеми автоматично.
- Документування: Ведіть записи про конфігурацію, зміни і помічені проблеми.
- Планування ресурсів: Використовуйте дані моніторингу для обґрунтованого планування розширення інфраструктури.
- Резерви: Завжди залишайте деякий запас ресурсів на гіпервізорі для пікових навантажень або непередбачених ситуацій.
Висновки
Перевірка навантаження на гіпервізор — це не разова акція, а безперервний процес, що вимагає уважності і використання правильних інструментів. Розуміння ключових метрик, вміння працювати з CLI-утилітами і використання централізованих систем моніторингу дозволяють вам не тільки оперативно реагувати на виникаючі проблеми, але і проактивно управляти продуктивністю вашої віртуальної інфраструктури. В кінцевому підсумку, це запорука стабільності, ефективності і відмовостійкості ваших сервісів. Тримайте руку на пульсі, колеги, і ваша інфраструктура скаже вам "спасибі"!
Оптимізуйте навантаження гіпервізора з гнучкими хмарними рішеннями
Масштабуйте ресурси на вимогу, щоб легко справлятися з піковими навантаженнями і забезпечувати стабільну продуктивність. Почніть роботу з нашими хмарними інстансами сьогодні.
Почати в хмарі →